With growing test architecture, we are facing various problems. Execution time, flakiness, duplicate test cases etc. Tests are becoming hard to manage and we may start to feel like writing and maintaining them is meaningless.
While lurking on reddit I came across a discussion about test types. Then it hit me - why can’t we categorize them and instead of one long run, perform them group by group? We won’t lose any coverage, and we’ll reduce time to market. 🥳
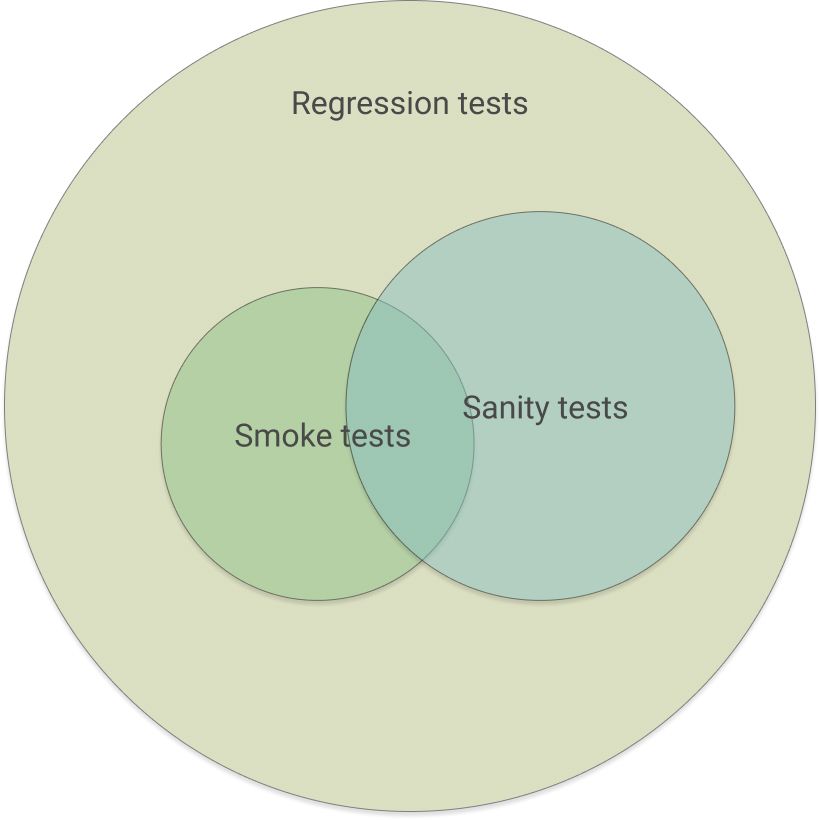
Types of end-to-end tests
Sticking to E2E tests only, after reading the reddit discussion and thinking about the topic, I’ve decided classify them into:
- smoke testing,
- sanity testing,
- regression testing.
You probably already know the last group very well (if not → click here).
Now let’s dig into each of the types mentioned before.
Smoke testing
The main characteristics of these tests are:
- They’re performed to cover critical functionalities of the application (Priority1 scenarios),
- The objective is to verify “stability” of the application to continue with further testing,
- They’re a subset of regression tests,
- They’re like a general health check up,
- Failing these tests results in instant rejection.
Simply speaking, smoke testing should cover the most critical parts, the ones that let us confirm that the applications is working and delivers business value.
For example, this kind of scenario could be in this category:
- [Netflix.com] User can log in, choose a tv series/movie and start watching.
Sanity testing
Next group is sanity tests, whose main aspects are:
- They’re performed to check more detailed functionalities of the application (Priority2 scenarios),
- The objective is to verify “rationality” of the application to continue with further testing,
- They’re a subset of regression tests,
- They’re like a detailed health check-up,
In simple words, sanity tests should cover more specialized user actions.
Here’s an example of a scenario that falls into this category:
- [Netflix.com] User can search for movies using search bar.
As you can imagine, sanity tests may have some test cases in common with smoke tests but also there are certain differences between these categories.
Regression testing
Last but not least - regression tests:
- They’re performed to check detailed functionalities of the application (Priority1 + Priority2 + Priority3 scenarios)
- The objective is to verify every existing feature of the application,
- Regression test cases should be well documented,
- They’re like a comprehensive health check-up,
Simply speaking, regression tests should cover all the aspects of application - the important and less important ones. Executing regression tests should give us an overview that everything works properly.
For example, a scenario that could be in this category is:
- [Netflix.com] User can open “more information” about a tv series/movie and choose genre.
Amount of tests by type
Regression tests > Sanity tests > Smoke tests.
And here’s a visual representation of how the sets intersect.
Arrange a deployment process based on test types
I’ve worked with one test database and deployment process for a while, and I figured that it’s not perfect and not bad, but as it grows, it needs some changes.
Depending on the type of tests, we can choose the most important ones and those that are less important. As we all know, the most important ones are those that deliver the business value, so we have to check if those functionalities work as expected with every deploy. Based on these criteria we can design our deployment process.
Working with an application based on CI/CD carries potential challenges such as designing a deployment process with automation testing. Because we don’t want it to be long, we can categorize the tests, and run each group at a different time.

As you can see, only smoke tests are run with each application deploy. This way we’ll always know that the most important functionalities work.
Conclusion
As the number of your tests grows, they become harder to maintain. Running all of them after every deployment consumes too much time. If you organize them into categories you will reduce time to market without losing any necessary coverage.
How you categorize your tests depends on you. They don’t necessarily need to be divided into smoke, sanity and regression categories. You can do it differently, for example, by criticality level.
Automated testing in deployment process is a standard practice in modern software development, used by the best teams and companies. CI/CD should therefore depend on the results of our tests, which will ensure that the critical functionalities always work.
Have a nice day! 🥳